My paper Similarity of the dog and human gut microbiomes in gene content and response to diet was published yesterday in Microbiome. It was a long time in the making (and almost a year in the review process: submitted 11 May 2017), but now it’s finally published! It has been picking up quite a bit of press, which is nice too.
It’s open access, so everyone can read it, but here’s a basic summary:
- We built a non-redundant gene catalog for the dog gut microbiome. We then compared it to the equivalent gene catalogs for humans, mice, and pigs (since all these catalogs were built on Illumina data using MOCAT, they were easily comparable). Somewhat surprisingly, we found a high overlap between the dog microbiome genes and that of the human microbiome (higher than for the other non-human animals).
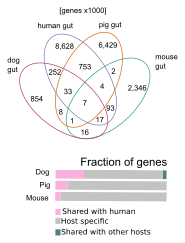 We can also map a much higher fraction of short reads from the dog gut microbiome to the human gut gene catalog than for the other non-human hosts.
We can also map a much higher fraction of short reads from the dog gut microbiome to the human gut gene catalog than for the other non-human hosts.

- When we used metaSNV to analyse the SNV, we saw strain separation between the human and dog strains (for the same species). Thus, we do not share organisms with our dogs! Only similar species. I have presented this conclusion (in talks and informally) and different people in the field told be both that “of course strains are host specific” and “I was expecting that we’d be getting bacteria from our dogs all the time, this is not what I expected at all.”

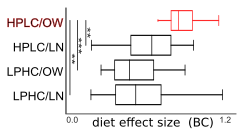
- Diet shifts the microbiome of the dogs (the dogs were randomly assigned to either a high-protein or a low-protein diet). We had two samples from each dog: one after they ate the baseline diet (which was a low-protein diet) and a second after the random switch to a high-protein diet. We could thus the microbiome of overweight dogs changes more than that of their healthier counterparts (see the Anna Karenina hypothesis: unhappy microbiomes are less alike).
 (in the Figure, HPLC/OW refers to overweight dogs on the high-protein diet).
(in the Figure, HPLC/OW refers to overweight dogs on the high-protein diet). - We also saw that some taxa dramatically changed their prevalence in response to the diet. In particular, Lactobacillus ruminis was completely absent in the high-protein diet. Not just lower abundant, but undetectable.



Those are the highlights, the full paper has a bit more. I’ll try to post a couple of extra posts with some interesting technical tidbits. For example, how we used the little-known Gehan statistic.

2 thoughts on “Similarity of the dog and human gut microbiomes in gene content and response to diet”